抢占调度
go 1.14 版本带来了一个非常重要的特性:异步抢占的调度模式。之前我们通过解释一个简单的协程调度原理(),并且实现协程调度例子都提到了一个点:协程是用户态实现的自我调度单元,每个协程都是君子才能维护和谐的调度秩序,如果出现了流氓(占着 cpu 不放的协程)你是无可奈何的。
go1.14 之前的版本所谓的抢占调度是怎么样的:
- 如果 sysmon 监控线程发现有个协程 A 执行之间太长了(或者 gc 场景,或者 stw 场景),那么会友好在这个 A 协程的某个字段设置一个抢占标记 ;
- 协程 A 在 call 一个函数的时候,会复用到扩容栈(morestack)的部分逻辑,检查到抢占标记之后,让出 cpu,切到调度主协程里;
这样 A 就算是被抢占了。我们注意到,A 调度权被抢占有个前提:A 必须主动 call 函数,这样才能有走到 morestack 的机会(旁白:能抢君子调度权利,抢占不了流氓的)。
举个栗子,然后看下 go1.13 和 go1.14 的分析对比:
特殊处理:
- 为了研究方便,我们只用一个 P(处理器),这样就确保是单处理器的场景;
- 回忆下 golang 的 GMP 模型:调度单元 G,线程 M,队列 P,由于 P 只有一个,所以每时每刻有效执行的 M 只会有一个,也就是单处理器的场景(旁白:个人理解有所不同,有些人喜欢直接把 P 理解成处理器,我这里把 P 说成队列是从实现的角度来讲的);
- 打开 golang 调试大杀器 trace 工具(可以直观的观察调度的情况);
- 搞一个纯计算且耗时的函数
calcSum(不给任何机会);
下面创建一个名为 example.go 的文件,写入以下内容:
package main
import (
"fmt"
"os"
"runtime"
"runtime/trace"
"sync"
)
func calcSum(w *sync.WaitGroup, idx int) {
defer w.Done()
var sum, n int64
for ; n < 1000000000; n++ {
sum += n
}
fmt.Println(idx, sum)
}
func main() {
runtime.GOMAXPROCS(1)
f, _ := os.Create("trace.output")
defer f.Close()
_ = trace.Start(f)
defer trace.Stop()
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go calcSum(&wg, i)
}
wg.Wait()
}
我们分别看下 go1.13, go.14 对于这个程序的表现区别。
trace 这个就再简单提下,trace 是 golang 内置的一种调试手段,能够 trace 一段时间程序的运行情况。能看到:
- 协程的调度运行情况;
- 跑在每个处理器 P 上协程情况;
- 协程出发的事件链;
编译、运行的程序:
$ go build -gcflags "-N -l" ./example.go
$ ./example
这样在本地就能生成一个 trace.output 文件;
分析 trace 输出:
$ go tool trace -http=":6060" ./trace.output
提一点,如果你的浏览器 View trace 是空白页没有任何显示,那么原因是:浏览器的一些 js 接口被禁用了。
Trace Viewer is running with WebComponentsV0 polyfill, and some features may be broken. As a workaround, you may try running chrome with “–enable-blink-features=ShadowDOMV0,CustomElementsV0,HTMLImports” flag. See crbug.com/1036492.
解决方法有两个:
1)加上参数,打开浏览器的参数开关 2)使用 go1.14 分析渲染,因为 go1.14 解决了这个问题;
go tool trace
在后台执行命令:
$ go tool trace -http=":6060" ./trace.output
这样就能分析 trace.output 这个文件了,可以用浏览器来方便查看分析的结果,如下:

名词解释:
- View trace:查看跟踪(这个是今天要使用的重点),能看到一段时间内 goroutine 的调度执行情况,包括事件触发链;
- Goroutine analysis:Goroutine 分析,能看到这段时间所有 goroutine 执行的一个情况,执行堆栈,执行时间;
- Network blocking profile:网络阻塞概况(分析网络的一些消耗)
- Synchronization blocking profile:同步阻塞概况(分析同步锁的一些情况)
- Syscall blocking profile:系统调用阻塞概况(分析系统调用的消耗)
- Scheduler latency profile:调度延迟概况(函数的延迟占比)
- User defined tasks:自定义任务
- User defined regions:自定义区域
- Minimum mutator utilization:Mutator 利用率使用情况
我们今天分析抢占调度,只需要看 View trace 这个展示就行了。
View trace

- 横坐标为时间线,表示采样的顺序时间;
- 纵坐标为采样的指标,分为两大块:STATS,PROCS
(这些采样值都要配合时间轴来看,你可以理解成是一些快照数据)
STATS
处于上半区,展示的有三个指标 Goroutines,Heap,Threads,你鼠标点击彩色的图样,就能看到这一小段时间的采样情况:
- Goroutines:展示某个时间 GCWaiting,Runnable,Running 三种状态的协程个数;
- Heap:展示某个时间的 NextGC,Allocated 的值;
- Threads:展示 InSyscall,Running 两个状态的线程数量情况;
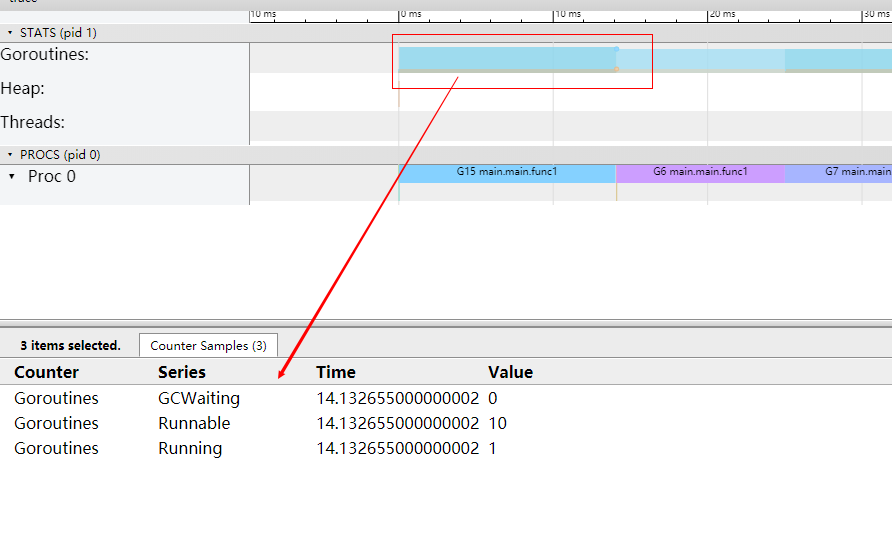
PROCS
- 显示每个处理器当时正在处理的协程,事件,和一些具体运行时信息;
- Proc 的个数由 GOMAXPROCS 参数控制,默认和机器核心数一致;
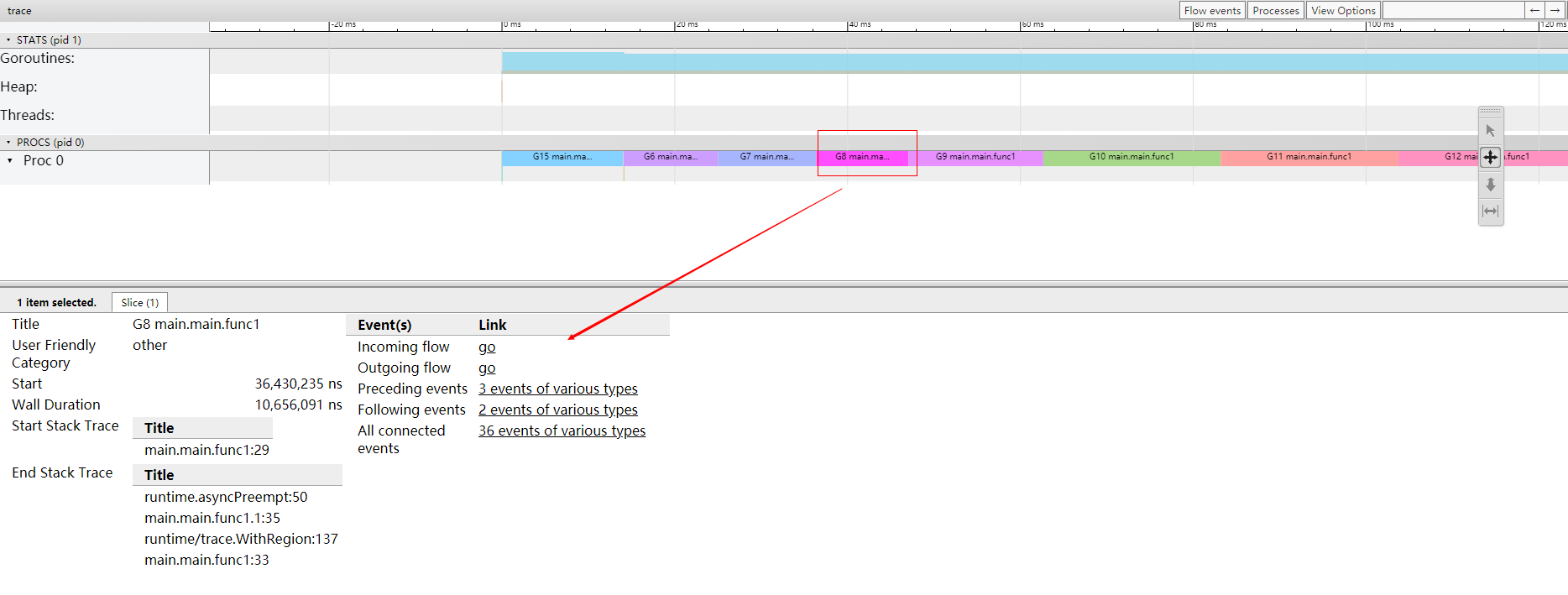
你点击一个协程区域,就会显示这个时间段的情况,有一些指标:
- Start:开始时间(就是时间轴上的刻度)
- Wall Duration:持续时间(这个 goroutine 在这个处理器上连续执行的小段时间)
- Start Stack Trace:协程调用栈(切进来执行的 goroutine 调用栈)
- End Stack Trace:切走时候时候的调用栈
- Incoming flow:触发切入的事件
- Outgoing flow:触发切走的事件
- Preceding events:这个协程相关的之前所有的事件
- Follwing events:这个协程相关的之后所有的事件
- All connected:这个协程相关的所有事件
golang 抢占调度
现在有了 View trace 的基础知识,我们用来观察 go1.13 和 go1.14 的抢占情况。编译 exmaple.go 文件,然后执行生成 trace.output 文件,go tool trace 分析这个文件,结果如下:
go1.13 trace 分析
trace 内部分析如下:
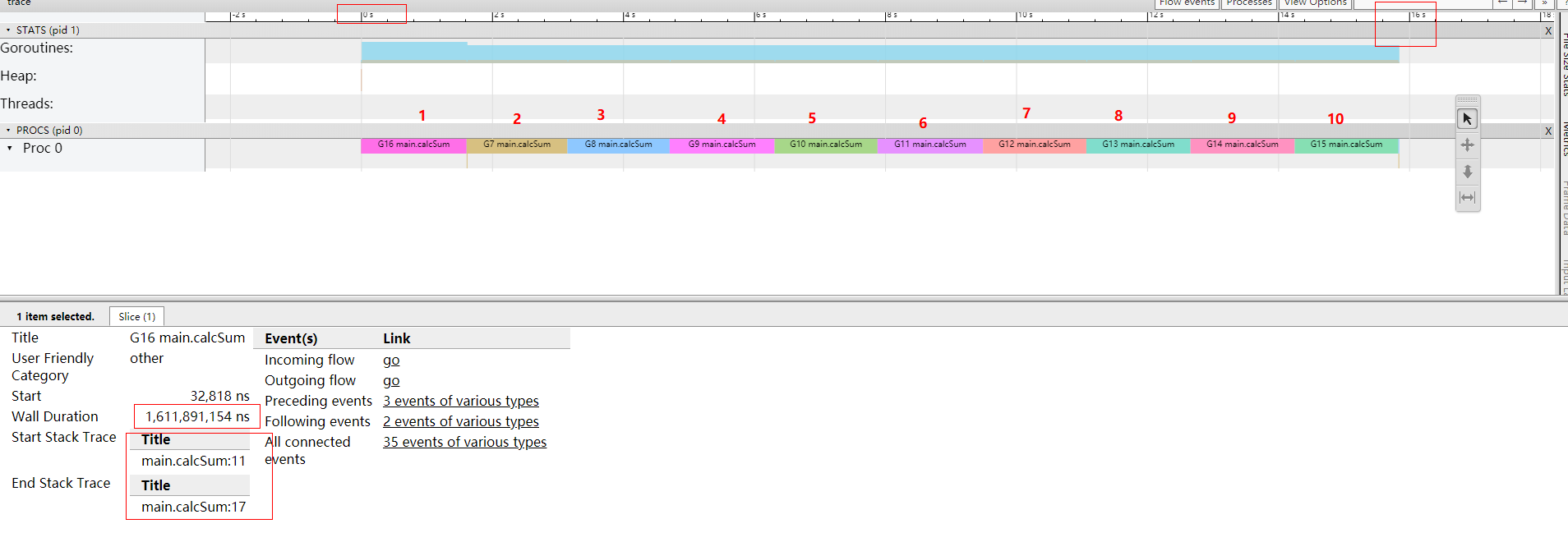
从 trace 这个图我们可以非常直观的得出一些信息:
- 只有一个处理器(Proc 0)调度协程;
- 因为我们代码里面设置
GOMAXPROCS = 1
- 因为我们代码里面设置
- 一共有 10 协程执行(可以数一下);
- example.go 的 for 循环就是 10 次
- 10 个协程在 Proc 0 上是串行执行的,从图里非常明显可以看到,执行完之后 goroutine 才会执行下一个协程,无法抢占;
- 每个 goroutine 连续执行 1.6s 左右,10 个协程执行时间总的时间耗费 16 s;
- 协程切入是从
main.calcSum:11切入的,切出是从main.calcSum:17切出的(fmt.Println 这个函数);
所以从这个 trace 分析,我们明确的看到,针对 calcSum 这样的流氓函数,go1.13 是毫无办法的,一旦执行开始,只能等执行结束。每个 goroutine 耗费了 1.6s 这么长的时间,也无法抢占他的执行权。
go1.14 trace 分析
现在我们看下用 go1.14 编译出的同一份程序,运行的 trace 结果:
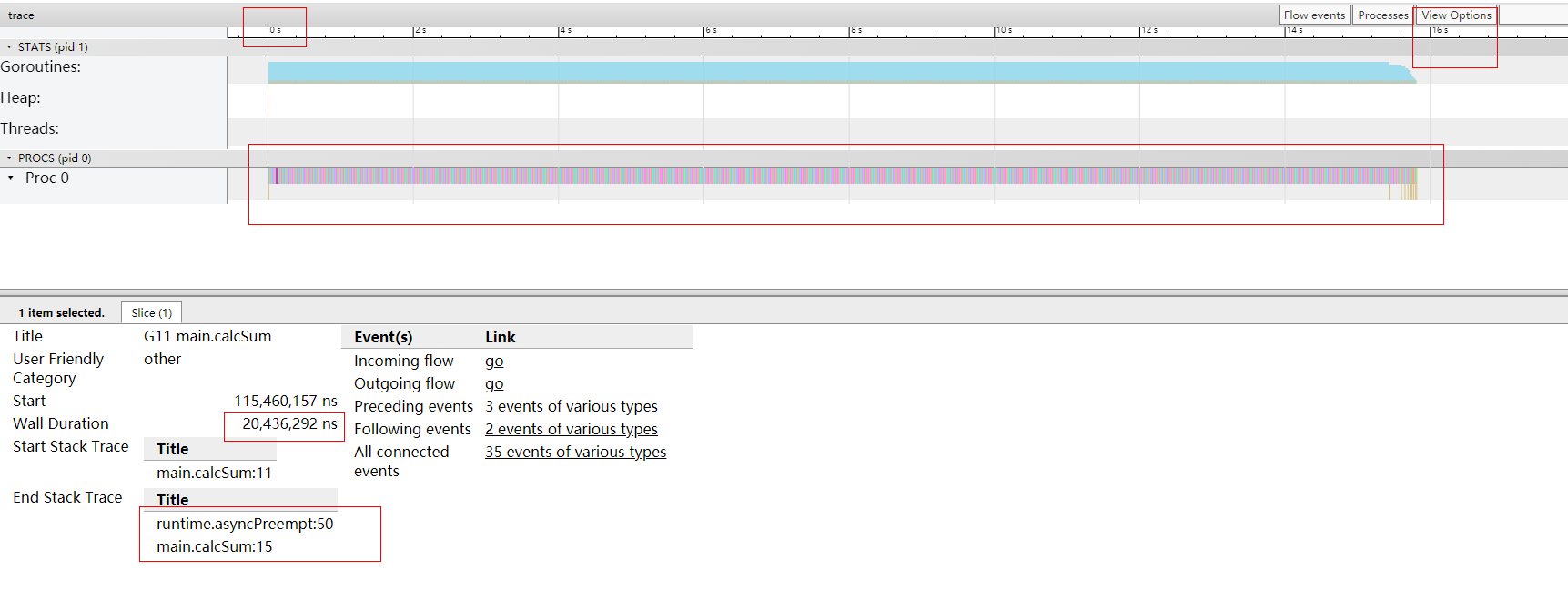
猛的一看,密密麻麻的,红蓝相间的细条。我下面详细的说明,我们选中一个片段,并且看一下整体信息:
- 还是只有一个处理器(Proc 0)调度协程;
- 因为我们代码里面设置
GOMAXPROCS = 1
- 因为我们代码里面设置
- 程序运行的总时间还是 16s(这个小伙伴能不能理解?虽然 10 个 goroutine 是并发运行的,但是你只有一个处理器,所以时间肯定是一样的,但如果你有多个处理器的时候,就不一样了);
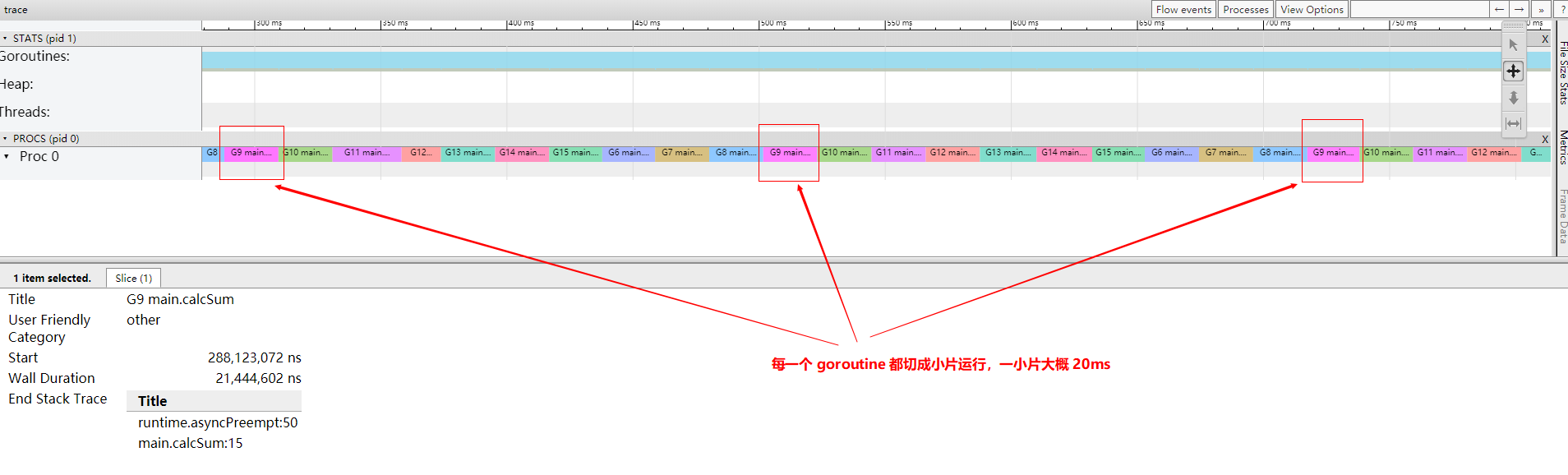
- 这个 goroutine 只执行了 20ms 就让出处理器了;
- 我们大概知道,example.go 里面
calcaSum函数在我的机器上大概需要 1.6s 的时间,所以执行 20ms 就切走了肯定是还没有执行完的,是被强制抢占了处理器;
- 我们大概知道,example.go 里面
- 切入的栈还是
main.calcSum:11,这个跟 go1.13 一样; - 切出的栈变了,
runtime.asyncPreempt:50这就是最大的不同,从这个地方也能明确的知道,被异步抢占了;
这样密密麻麻的红蓝片段,无法知道一共多少 goroutine?其实是可以的,可以通过 STATS 区来看:
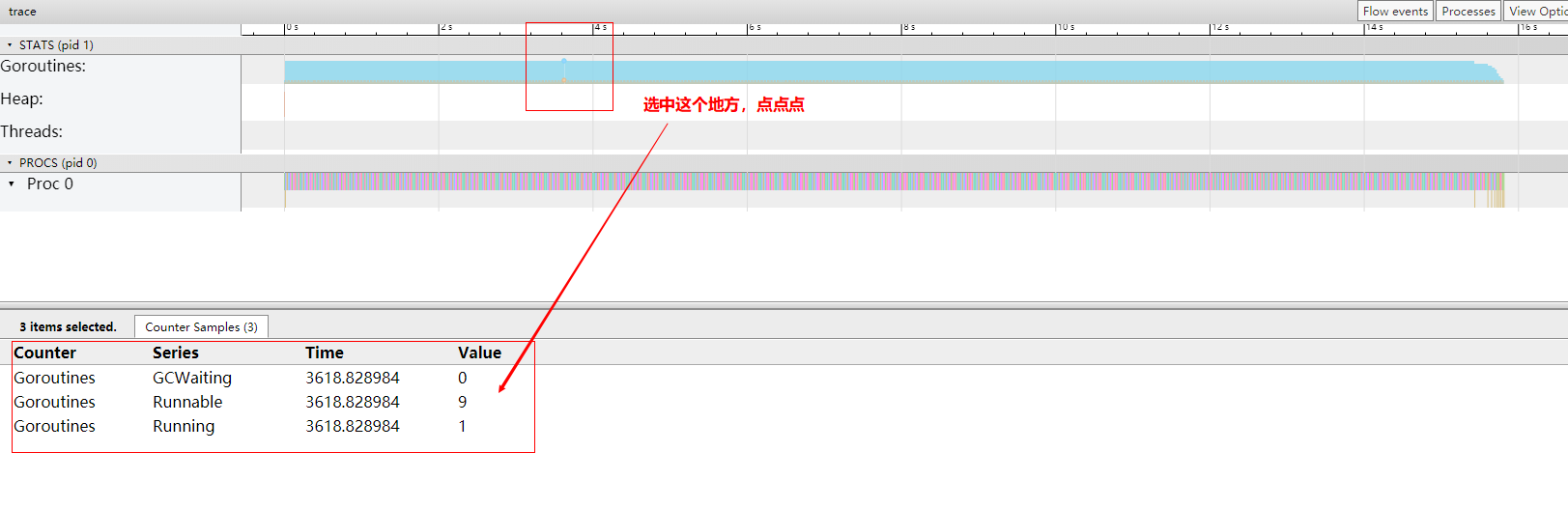
选中 Goroutines 区域,点点点,就会看到 Goroutines 的总数一直是 10 个,正在运行的 goroutine (Running)是 1 个,等待调度的(Runnable)是 9 个。
可以执行 W 快捷键,可以把图片放大:
思考问题
问题一:go1.14 确实带来了并发,我们看到在我们的 demo 里面,goroutine 的运行被强制切成了小段的时间片,所以再流氓的函数也不再害怕。但是为啥在我们 example.go 的演示里面,虽然 10 个 goroutine 全并发了,运行总时间却没有丝毫优化?
根本原因:只有一个处理器,所以,就算你做了多少并发,不同的 goroutine 反复横跳,效果还是一样的,因为只有一个处理器干活。
问题二:如果我用 2 个处理器呢?
先看结果:
go1.13

go 1.14
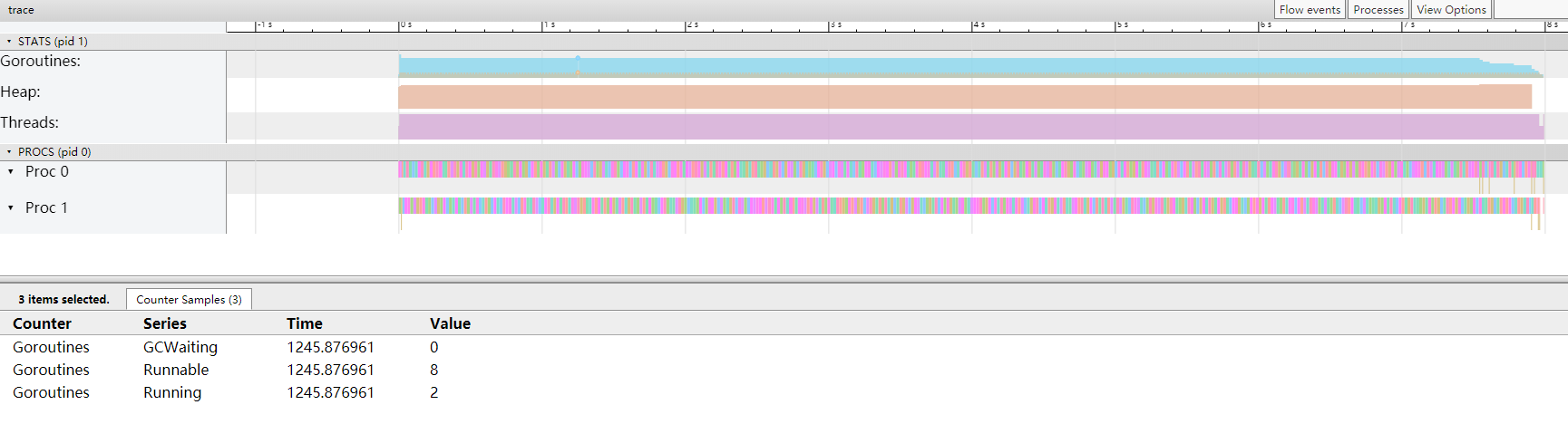
时间还是一样,都缩短一倍,8秒。
思考两个问题:
- 添加处理器后,时间为啥能缩短一倍(16s -> 8s)?
因为处理器变成 2 了,这个应该很容易理解,总共就 10 个 协程,之前一个处理器处理 10个,时间就耗费 16 s,现在 2 个处理器,每个处理器平均处理 5 个,处理器是并行运行的,所以自然时间就少一半了。
- 为啥 go1.13,go1.14 时间还是一样的?
根本原因在于:我们举的例子是纯计算类型的,每个协程的时间固定是 1.6 s,这个是没法减少的。16 个协程总时间是 16 s 这个是无法减少的。你只有两个处理器,最好的情况也就是 2 个处理器并行处理,时间完全减半。
问题三:那这种抢占行调度有啥用?
这种协程调度本质上是为了增加系统的吞吐能力。抢占型调度是为了让大家公平的得到调度,不会让系统因为某一个协程卡死(因为处理器资源有限),举个例子:
G1: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
G2: ||||
G3: ||||
G4: |||
假设:
- 只有一个处理器(GOMAXPROCS = 1);
- G1,G2,G3,G4 依次在调度队列里,并且这个协程都是纯计算的逻辑;
- G1 执行需要 1 小时,G2 执行需要 0.02 秒,G3 执行需要 0.02 秒,G4 执行需要 0.01 秒;
如果是 go1.13 这样不可抢占的模式,先执行 G1,那么一个小时之后再执行 G2,G3,G4,这段时间不能执行任何逻辑,相当于系统卡死 1 小时,1小时内无作为(并且还会堆积请求),系统吞吐率极低;
如果是 go1.14,那么先执行 G1,20ms之后,让出调度权,依次执行 G2,G3,G4 瞬间就完成了,并且之后有新的请求来,系统还是可以响应的,吞吐率高。尤其是在 IO 操作的情况,其实只需要一点点 cpu 就行了,这些抢占过来的 cpu 能够用在很多更有效的场景。
总结
- go1.14 带来了真正的抢占式任务调度,让 goroutine 任务的调度执行更加公平,避免了流氓协程降低整个系统吞吐能力的情况发生;
- 本片文章从简单栗子入手,通过 trace 工具图形化展示了在 go1.13 和 go1.14 的调度执行情况,从 trace 结果来看,实锤,非常直观;
- 我们理解了抢占调度带来的好处,并且形象的观测到了,并且还发现了
runtime.asyncPreempt这个函数(后面会有个代码原理层面的详细梳理); - 我们顺便操作并解释了
go tool trace的使用,和参数含义,trace 工具可是个 golang 问题排查的大杀器,非常推荐;
坚持思考,方向比努力更重要。关注公众号:奇伢云存储,获取更多干货。
