之前阐述了 golang 垃圾回收通过保证三色不变式来保证回收的正确性,通过写屏障来实现业务赋值器和 gc 回收器正确的并发的逻辑。其中高概率的提到了“扫描队列”和“扫描对象”。队列这个逻辑非常容易理解,那么”扫描对象“ 这个你理解了吗?有直观的感受吗?这篇文章就是要把这个扫描的过程深入剖析下。
- 扫描的东西是啥?形象化描述下
- 怎么去做的扫描?形象化描述下
我们就是要把这两个抽象的概念搞懂,不能停留在语言级别浅层面,要知其然知其所以然。
扫描的目的
扫描到底是为了什么?
之前的文章我们深入剖析了垃圾回收的理论和实现,可以总结这么节点:
- 垃圾回收的根本目的是:“回收那些业务永远都不会再使用的内存块”;
- 扫描的目的则是:“把这些不再使用的内存块找出来”;
我们通过地毯式的扫描,从一些 root 起点开始,不断推进搜索,最终形成了一张有向可达的网,那些不在网里的就是没有被引用到的,也就是可回收的内存。
扫描的实现
扫描对象代码逻辑其实不简单,但主体线索很清晰,可以分为三部分:
- 编译阶段:编译期是非常重要的一环,针对静态类型做好标记准备(旁白:原则上编译期能做的绝对不留到运行期);
- 运行阶段:赋值器分配内存的时候,根据编译阶段的 type 标示,会为分配的对象内存设置好一个对应的指针标示的 bitmap;
- 扫描阶段:根据指针的 bitmap 标示,地毯式扫描;
编译阶段
结构体对齐
要理解编译阶段做的事情,那么首先要理解结构体对齐的基础知识。这个和 C 语言类似,golang 的结构体是有对齐规则的,也就是说,必要的时候可能会填充一些内存空间来满足对齐的要求。总结来说两条规则:
- 长度要对齐
- 地址要对齐
“长度要对齐”怎么理解?
结构体的长度要至少是内部最长的基础字段的整数倍。
举例:
type TestStruct struct {
ptr uintptr // 8
f1 uint32 // 4
f2 uint8 // 1
}
这个结构体内存占用 size 多大?
答案是:16个字节,因为字段 ptr 是 uintptr 类型,占 8 字节,是内部字段最大的,TestStruct 整体长度要和 8 字节对齐。那么就是 16 字节了,而不是有些人想的 13 字节(8+4+1)。
dlv 调试如下:
(dlv) p typ
*runtime._type {
size: 16,
...
字节示意图:
|--8 Byte--|--4 Byte--|--4 Byte--|
“地址要对齐”怎么理解?
字段的地址偏移要是自身长度的整数倍。
举例:
type TestStruct struct {
ptr uintptr // 8
f1 uint8 // 1
f2 uint32 // 4
}
假设 new 一个 TestStruct 结构体 a 的地址是 0xc00008a010 ,那么 &a.ptr 是 0xc00008a010 (= a + 0),&a.f1 是 0xc00008a018 (= a + 8) ,&a.f2 是 0xc00008a01c (= a + 8 + 4) 。
dlv 调试如下:
(dlv) p &a.ptr
(*uintptr)(0xc00008a010)
(dlv) p &a.f1
(*uint8)(0xc00008a018)
(dlv) p &a.f2
(*uint32)(0xc00008a01c)
假设 TestStruct 分配对象 a 的地址是 0xc00008a010 ,解释如下:
- ptr 是第一个字段,当然和结构体本身地址一样,相对偏移是 0,所以地址是
0xc00008a010 == 0xc00008a010 + 0; - f1 是第二个字段,由于前一个字段 ptr 是 uintptr 类型(8字节),并且由于 f1 本身是 uint8 类型(1字节),所以 f1 从 8 偏移开始没毛病,所以 f1 的偏移地址从
0xc00008a018 == 0xc00008a010 + 8; - f2 是第三个字段,由于前一个字段 f1 是 uint8(1字节),所以表面上看好像 f2 要接着
0xc00008a019(= 0xc00008a018 +1) 这个地址才对,但是 f2 本身是 uint32 (4字节的类型),所以 f2 地址偏移至少要是 4 的倍数,所以 f2 的地址要从0xc00008a01c(0xc00008a018 + 4)这个地址开始才对。也就是说,f1 到 f2 之间填充了一些不用的空间,为了地址对齐。
所以这样算下来,整个 TestStruct 的占用空间长度是 16字节 (8+1+3+4)。
指针位标记
golang 的所有类型都对应一个 _type 结构,可以在 runtime/type.go 里面找到,定义如下:
type _type struct {
size uintptr
ptrdata uintptr // size of memory prefix holding all pointers
hash uint32
tflag tflag
align uint8
fieldalign uint8
kind uint8
alg *typeAlg
// gcdata stores the GC type data for the garbage collector.
// If the KindGCProg bit is set in kind, gcdata is a GC program.
// Otherwise it is a ptrmask bitmap. See mbitmap.go for details.
gcdata *byte
str nameOff
ptrToThis typeOff
}
比如我们定义了一个 Struct 如下:
type TestStruct struct {
ptr uintptr
f1 uint8
f2 *uint8
f3 uint32
f4 *uint64
f5 uint64
}
该结构 dlv 调试如下:
(dlv) p typ
*runtime._type {
size: 48,
ptrdata: 40,
hash: 4075663022,
tflag: tflagUncommon|tflagExtraStar|tflagNamed (7),
align: 8,
fieldalign: 8,
kind: 25,
alg: *runtime.typeAlg {hash: type..hash.main.TestStruct, equal: type..eq.main.TestStruct},
gcdata: *20,
str: 28887,
ptrToThis: 49504,}
在编译期间,编译器就会在内部生成一个 _type 结构体与之对应。_type 里面重点解释几个和本次扫描主题相关的字段:
- size:类型长度,我们上面这个类型长度应该是 32 字节;
- 这里理解要应用上上面讲的结构体字节对齐的知识,这里就不再复述;
- ptrdata:指针截止的长度位置,我们 f4 是指针,所以包含指针的字段最多也就到 40 字节的位置,ptrdata==40;
- 要理解字节对齐哈;
- kind:表明类型,我们是自定义struct类型,所以 kind == 25
- kind 枚举定义在
runtime/typekind.go文件里;
- kind 枚举定义在
- gcdata:这个就重要了,这个就是指针的 bitmap,因为编译器他在编译分析的时候,肯定就知道了所有的类型结构,那么自然知道所有的指针位置。gcdata 是
*byte类型(byte 数组),当前值是 20,20 转换成二进制数据就是00010100,这个眼熟不?这个你要从右往左看就是00101000(从低 bit 往高 bit 看),这个不就是刚好是TestStruct的指针 bitmap 嘛,每个 bit 表示一个指针大小(8 字节)的内存,00101000第 3 个 bit 和第 5 个 bit 是 1,表示 第 3 个字段(第 3 个 8 字节的位置)和第 5 个字段(第 5 个 8 字节的位置)是存储的是指针类型,这里刚好就和TestStruct.f2和TestStruct.f4对应起来。
划重点:这里重点回顾一下 uintptr 类型的问题,这里注意到,第一个字段 ptr(uintptr 类型)在指针的 bitmap 上是没有标记成指针类型的,这里一定要注意了,uintptr 是数值类型,非指针类型,用这个存储指针是无法保护对象的(扫描的时候 uintptr 指向的对象不会被扫描),这里就是实锤了。
小结:
编译阶段给每个类型生成 _type 类型,内部对类型字段生成指针的 bitmap,这个是后面扫描行为的基础依据。
思考题:是否可以不用 bitmap,其实有个最简单最笨拙的扫描方式,我们可以不搞这个指针的 bitmap,我上来就直接扫描,每 8 字节的读取内存,然后去看这个内存块存储的值是否指向了一个对象?如果是我就保护起来。
这个实现理论上可以满足,但是有两个不能接受的缺陷:
- 精度太低,你编译期间不做准备,那运行期间就要来偿还这部分损耗,你无法判断是不是指针,所以只要指向了一个有效内存地址,就得无脑保护,这样就保护了很多不需要保护的内存块;
- 扫描太低效,必须全地址扫描,因为你没有 bitmap,无法识别是否有指针。也无法做优化,比如我们程序里面可能 一半以上的类型内是不包含指针的,这种根本就不需要扫描;
运行期内存分配
下一步就是赋值器的做的事情,也就是业务运行的过程中分配内存。分配内存的时候肯定要指定类型,调用 runtime.newobject 函数进行分配,本质上调用 mallocgc 函数来操作。mallocgc 函数做几件事情:
- 分配内存
- 内存采样
- gc 标记准备
我们这里重点分析给 gc 做扫描做的准备。在分配完堆内存之后,会调用一个函数 heapBitsSetType ,这个函数逻辑非常复杂,但是做的事情其实一句话能概括:“给 gc 扫描做准备,对分配的内存块做好标记,这小块内存中,哪些位置是指针,我们用一个 bitmap 对应记录下来”。这就是 heapBitsSetType 500 多行代码做的所有事情,之所以这么复杂是因为要判断各种情况。
heapBitsSetType 主要逻辑解析:
func heapBitsSetType(x, size, dataSize uintptr, typ *_type) {
// ...
// 最重要的两个步骤:
// 通过分配地址反查获取到 heap 的 heapBits 结构(回忆下 golang 的内存地址管理)
h := heapBitsForAddr(x)
// 获取到类型的指针 bitmap;
ptrmask := typ.gcdata // start of 1-bit pointer mask (or GC program, handled below)
var (
// ...
)
// 把 h.bitp 这个堆上的 bitmap 取出来;
hbitp = h.bitp
// 该类型的指针 bitmap
p = ptrmask
// ...
if p != nil {
// 把 bitmap 第一个字节保存起来
b = uintptr(*p)
// p 指向下一个字节
p = add1(p)
//
nb = 8
}
// 我们的是简单的 Struct 结构(48==48)
if typ.size == dataSize {
// nw == 5 == 40/8,说明扫描到第 5 个字段为止即可。
// ptrdata 指明有指针的范围在[0, 40]以内,再往外确定就没有指针字段了;
nw = typ.ptrdata / sys.PtrSize
} else {
nw = ((dataSize/typ.size-1)*typ.size + typ.ptrdata) / sys.PtrSize
}
switch {
default:
throw("heapBitsSetType: unexpected shift")
case h.shift == 0:
// b 是类型的 ptr bitmap => 00010100
// bitPointerAll => 00001111
// hb => 0000 0100
hb = b & bitPointerAll
// bitScan => 0001 0000
// 0001 0000 | 0100 0000 | 1000 0000
// hb => 1101 0100
hb |= bitScan | bitScan<<(2*heapBitsShift) | bitScan<<(3*heapBitsShift)
// 赋值 hbitp => 1101 0100
*hbitp = uint8(hb)
// 指针往后一个字节(递进一个字节)
hbitp = add1(hbitp)
// b => 0000 0001
b >>= 4
// nb => 4
nb -= 4
case sys.PtrSize == 8 && h.shift == 2:
// ...
}
// ...
// 处理完了前 4 bit,接下来处理后 4 bit
nb -= 4
for {
// b => 0000 0001
// hb => 0000 0001
hb = b & bitPointerAll
// hb => 1111 0001
hb |= bitScanAll
if w += 4; w >= nw {
// 处理完了,有指针的字段都包含在已经处理的 ptrmask 范围内了
break
}
// ...
}
Phase3:
// Phase 3: Write last byte or partial byte and zero the rest of the bitmap entries.
// 8 > 5
if w > nw {
// mask => 1
mask := uintptr(1)<<(4-(w-nw)) - 1
// hb => 0001 0001
hb &= mask | mask<<4 // apply mask to both pointer bits and scan bits
}
// nw => 6
nw = size / sys.PtrSize
// ...
if w == nw+2 {
// 赋值 hbitp => 0001 0001
*hbitp = *hbitp&^(bitPointer|bitScan|(bitPointer|bitScan)<<heapBitsShift) | uint8(hb)
}
Phase4:
// Phase 4: Copy unrolled bitmap to per-arena bitmaps, if necessary.
// ...
}
所以,上面函数调用完,h.bitp 就给设置上了:
低字节 -> 高字节 [ 1101 0100 ], [ 0001 0001 ] |–前4*8字节–|–后4*8字节–|
这个就是 mallocgc 内存的时候做的事情。
总结就一句话:根据编译期间针对每个 struct 生成的 type 结构,来设置 gc 需要扫描的位图,也就是指针 bitmap。(旁白:每分配一块内存出去,我都会有一个 bitmap 对应到这个内存块,指明哪些地方有指针)。
运行扫描阶段
- 扫描以
markroot开始,从栈,全局变量,寄存器等根对象开始扫描,创建一个有向引用图,把根对象投入到队列中,重点的一个函数就是scanstack。 - 另外异步的
goroutine运行gcDrain函数,从队列里消费对象,并且扫描这个对象;- 扫描调用的就是
scanobject函数
- 扫描调用的就是
下面重点介绍:scanstack,scanobject 这个函数怎么扫描对象。
scanstack
这个函数是起点函数( 起始最原始的还是 markroot,但是我们这里梳理主线 ),该扫描栈上所有可达对象,因为栈是一个根,因为你做事情总要有个开始的地方,那么“栈”就是 golang 的起点。
func scanstack(gp *g, gcw *gcWork) {
// ...
// 扫描栈上所有的可达的对象
state.buildIndex()
for {
p := state.getPtr()
if p == 0 {
break
}
// 获取一个到栈上对象
obj := state.findObject(p)
if obj == nil {
continue
}
// 获取到这个对象的类型
t := obj.typ
// ...
// 获取到这个类型内存块的 ptr 的 bitmap(编译期间编译器设置好)
gcdata := t.gcdata
var s *mspan
if t.kind&kindGCProg != 0 {
s = materializeGCProg(t.ptrdata, gcdata)
gcdata = (*byte)(unsafe.Pointer(s.startAddr))
}
// 扫描这个对象
// 起点:对象起始地址 => state.stack.lo + obj.off
// 终点:t.ptrdata (还记得这个吧,这个指明了指针所在内的边界)
// 指针 bitmap:t.gcdata
scanblock(state.stack.lo+uintptr(obj.off), t.ptrdata, gcdata, gcw, &state)
if s != nil {
dematerializeGCProg(s)
}
}
// ...
}
小结::
- 找到这个 goroutine 栈上的内存对象(一个个找,一个个处理);
- 找到对象之后,获取到这个对象的 type 结构,然后取出 type.ptrdata, type.gcdata ,从而我们就知道扫描的内存范围,和内存块上指针的所在位置;
- 调用 scanblock 扫描这个内存块;
scanblock
scanblock 这个函数不说你应该知道,这是一个非常底层且通用的函数,他的一切参数都是传入的,这个函数作为一个基础函数被很多地方调用:
/*
b0: 扫描开始的位置
n0: 扫描结束的长度
ptrmask: 指针的 bitmap
*/
func scanblock(b0, n0 uintptr, ptrmask *uint8, gcw *gcWork, stk *stackScanState) {
b := b0
n := n0
// 扫描到长度 n 为止;
for i := uintptr(0); i < n; {
// 每个 bit 标识一个 8 字节,8个 bit (1个字节)标识 64 个字节;
// 这里计算到合适的 bits
bits := uint32(*addb(ptrmask, i/(sys.PtrSize*8)))
// 如果整个 bits == 0,那么说明这 8 个 8 字节都没有指针引用,可以直接跳到下一轮
if bits == 0 {
i += sys.PtrSize * 8
continue
}
// bits 非0,说明内部有指针引用,就必须一个个扫描查看;
for j := 0; j < 8 && i < n; j++ {
// 指针类型?只有标识了指针类型的,才有可能走到下面的逻辑去;
if bits&1 != 0 {
p := *(*uintptr)(unsafe.Pointer(b + i))
if p != 0 {
if obj, span, objIndex := findObject(p, b, i); obj != 0 {
// 如果这 8 字节指向的是可达的内存对象,那么就投入扫描队列(置灰)保护起来;
greyobject(obj, b, i, span, gcw, objIndex)
} else if stk != nil && p >= stk.stack.lo && p < stk.stack.hi {
stk.putPtr(p)
}
}
}
bits >>= 1
i += sys.PtrSize
}
}
}
如果以上面的 TestStruct 结构举例的话,假设在栈上分配了对象 TestStruct{},地址是 0xc00007cf20,那么会从这个地址扫描 scanblock ( 0xc00007cf20, 40, 20, xxx)
type TestStruct struct {
ptr uintptr
f1 uint8
f2 *uint8
f3 uint32
f4 *uint64
f5 uint64
}
示意图如下:
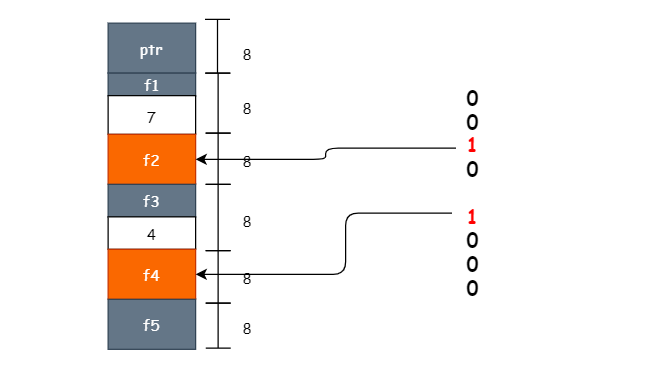
最外层 for 循环一次就够了,里面 for 循环 5 次,扫描到 f4 字段就完了(还记得 type.ptrdata == 40 吧 )。只有 f2 ,f4 字段才会作为指针去扫描。如果 f2, f4 字段存储的是有效的指针,那么指向的对象会被保护起来(greyobject)。
小结:
scanblock这个函数非常简单,只扫描给定的一段内存块;- 大循环每次递进 64 个字节,小循环每次递进 8 字节;
- 是否作为指针扫描是由 ptrmask 指定的;
- 只要长度和地址是对齐的,指针类型按 8 字节对齐,那么我们按照 8 字节递进扫描一定是全方位覆盖,不会漏掉一个对象的;
- 再次提醒下,uintptr 是数值类型,编译器不会标识成指针类型,所以不受扫描保护;
scanobject
gcDrain 这个函数就是从队列里不断获取,处理这些对象,最重要的一个就是调用 scanobject 继续扫描对象。
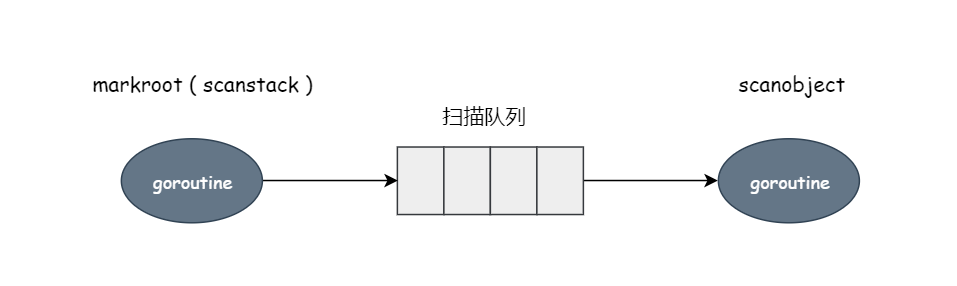
markroot 从根(栈)扫描,把扫描到的对象投入扫描队列。gcDrain 等函数从里面不断获取,不断处理,并且扫描这些对象,进一步挖掘引用关系,当扫描结束之后,那些没有扫描到的就是垃圾了。
还是 TestStruct 举例:
type TestStruct struct {
ptr uintptr
f1 uint8
f2 *uint8
f3 uint32
f4 *uint64
f5 uint64
}
如果一个创建在堆上的 TestStruct 对象被投入到扫描队列,对应的 type.gcdata 是 0001 0100 ,TestStruct 对应编译器创建的 type 类型如下:
(dlv) p typ
*runtime._type {
size: 48,
ptrdata: 40,
...
gcdata: *20,
... }
scanobject 逻辑如下:
/*
b : 是对象的内存地址
gcw : 是扫描队列的封装
*/
func scanobject(b uintptr, gcw *gcWork) {
// 通过对象地址 b 获取到这块内存地址对应的 hbits
hbits := heapBitsForAddr(b)
// 通过对象地址 b 获取到这块内存地址所在的 span
s := spanOfUnchecked(b)
// span 的元素大小
n := s.elemsize
if n == 0 {
throw("scanobject n == 0")
}
// ...
var i uintptr
// 每 8 个字节处理递进处理(因为堆上对象分配都是 span,每个 span 的内存块都是定长的,所以扫描边界就是 span.elemsize )
for i = 0; i < n; i += sys.PtrSize {
if i != 0 {
hbits = hbits.next()
}
// 获取到内存块的 bitmap
bits := hbits.bits()
// 确认该整个内存块没有指针,直接跳出,节约时间;
if i != 1*sys.PtrSize && bits&bitScan == 0 {
break // no more pointers in this object
}
// 确认 bits 对应的小块内存没有指针,所以可以直接到下一轮
// 如果是指针,那么就往下看看这 8 字节啥情况
if bits&bitPointer == 0 {
continue // not a pointer
}
// 把这 8 字节里面存的值取出来;
obj := *(*uintptr)(unsafe.Pointer(b + i))
// 如果 obj 有值,并且合法(不在一个 span 的内存块里)
if obj != 0 && obj-b >= n {
// 如果 obj 指向一个有效的对象,那么把这个对象置灰色,投入扫描队列,等待处理
if obj, span, objIndex := findObject(obj, b, i); obj != 0 {
greyobject(obj, b, i, span, gcw, objIndex)
}
}
}
// ...
}
小结:
- scanobject 的目的其实很简单:就是进一步发现引用关系,尽可能的把可达对象全覆盖;
- 这个地方就没有直接使用到 type ,而是使用到 mallocgc 时候的准备成果( heapBitsSetType 设置),每个内存块都对应了一个指针的 bitmap;
总结
- 要达到“正确并且高效的扫描”需要 编译期间,运行分配期间,扫描期间 三者配合处理;
- 内存对齐是非常重要的一个前提条件;
- 编译期间生成 type 类型,对用户定义的类型全方位分析,标记出所有的指针类型字段;
- 运行期间,赋值器分配内存的时候,根据 type 结构,设置和对象内存一一对应的 bitmap,标明指针所在位置,以便后续 gc 扫描;
- 回收器扫描期间,从根部开始扫描,遇到对象,则置灰,投入队列,并且不断的扫描这些对象指向的对象,直到结束。扫描的依据,就根据编译期间生成的 bitmap,分配期间设置的 bitmap 来识别哪些地方有指针,然后进一步处理;
- 扫描只需要给个开始地址,然后每 8 字节推进就可以扫描了,为了加快效率我们才有了指针的 bitmap (所以这个是个优化项);
- 再次强调下,定义的非指针类型不受保护,比如 uintptr 里面就算存储的是一个地址的值,也是不会被扫描到的;
坚持思考,方向比努力更重要。关注公众号:奇伢云存储,获取更多干货。
