前情概要
有位读者群里抛出过一段自己研究的代码,并附上这么一个问题:

代码截屏:
为了刚好的研究,下面贴出来代码文本:
package main
import (
"fmt"
"reflect"
"unsafe"
)
func StringToByte(key *string) []byte {
strPtr := (*reflect.SliceHeader)(unsafe.Pointer(key))
strPtr.Cap = strPtr.Len
b := *(*[]byte)(unsafe.Pointer(strPtr))
return b
}
func main() {
decryptContent := "/AvYEjm4g6xJ3LVrk2/Adk"
iv := decryptContent[0:16]
key := decryptContent[2:18]
fmt.Println(&iv)
fmt.Println(&key)
ivBytes := StringToByte(&iv)
keyBytes := StringToByte(&key)
fmt.Println(string(ivBytes))
fmt.Println(string(keyBytes))
}
思考第一个问题:为什么会报错?
我自己也编译跑了下,确实是得到如下错误。为什么会出现这个问题?其实文章标题都已经说明了,就是踩内存。那现在我们就是要先分析怎么踩的内存?
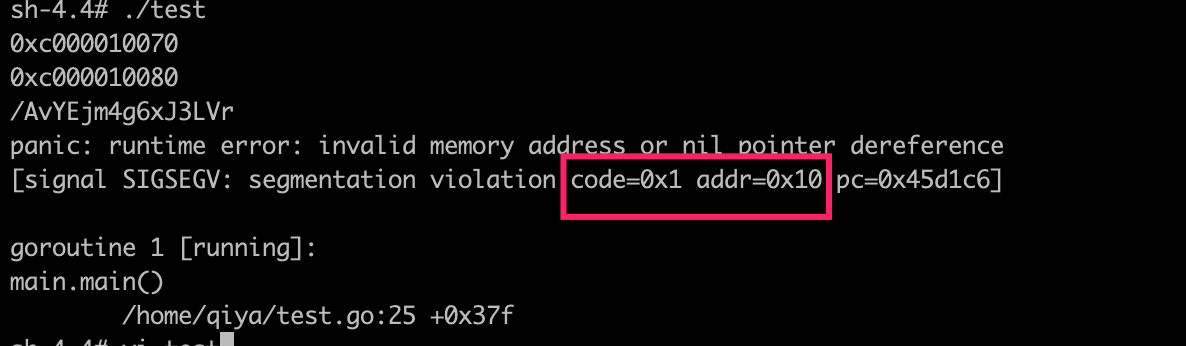
sh-4.4# ./test
0xc0000821e0
0xc0000821f0
/AvYEjm4g6xJ3LVr
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x10 pc=0x45d1c6]
goroutine 1 [running]:
main.main()
/home/qiya/test.go:25 +0x37f
之前我在深入剖析 Go nil 的文章里有提到过,一定要理解变量结构体本身和被管理的结构。
字符串类型的变量,本身占用 16 字节,有一个指针指向一块内存,这个内存才是字符串存储的位置,还有一个长度字段标识字符串的长度。如下:
type string struct {
uint8 *str;
int len;
}
slice 的变量本身占用 24 字节,有 3 个 8 字节的字段。Data 指向一个 byte 内存块,Len 标识当前有效的元素位置,Cap 标识这个动态数组的物理长度。
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
现在我们在仔细看下程序里面的 StringToByte 函数,我们看到在 main 函数里,直接取了 key,iv 这两个变量本身的地址,作为参数传进了 StringToByte ,随后在这个函数里,把这个地址通过 unsafe 库强转类型,当作 slice 管理结构来用,重点来了,且覆盖写 strPtr.Cap 这个字段。这就踩内存了,往后多踩了 8 字节的内存。
我就代码执行一步步分析下:
执行完以下代码:
decryptContent := "/AvYEjm4g6xJ3LVrk2/Adk"
iv := decryptContent[0:16]
key := decryptContent[2:18]
内存栈如下:
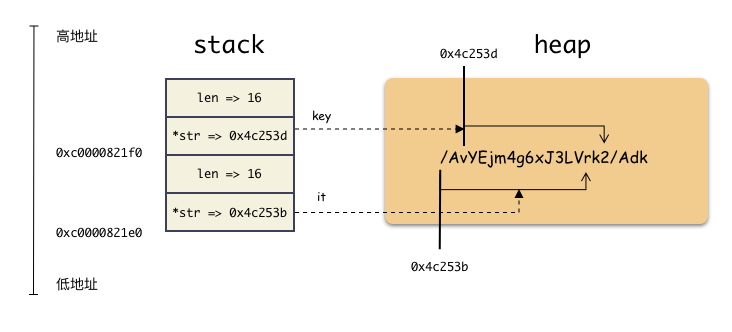
在看 22,23 的代码:
ivBytes := StringToByte(&iv)
keyBytes := StringToByte(&key)
然后,经过 22 行代码执行第一个 StringToByte 函数之后(也就是第一次踩内存),由于传进去的是变量 iv 的地址,于是在函数 StringToByte 里往后多踩了 8 字节,也就是说把变量 key 的头 8 字节踩掉了。效果如下:
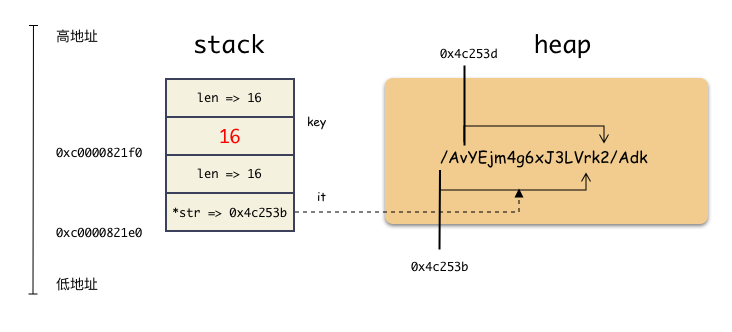
key 的头 8 个字节原本是个地址,指向堆上内存字符串所在位置。现在却被无情的踩成了一个整数 16 。
然后, StringToByte 函数把这 24 个字节复制给一个栈上的局部变量 ivBytes , ivBytes 的变量值如下:
*str => 0x4c253b
len => 16
cap => 16
接着,运行了第 23 行,又执行了一次 StringToByte 的函数,这次传入的地址是 key 变量的地址,又是往后踩了 8 字节。这次踩到谁了?看一眼 key 变量里现在的内容,哈哈哈,如下:
(gdb) x/14gx 0xc0000821f0
0xc0000821f0: 0x0000000000000010 0x0000000000000010
0xc000082200: 0x0000000000000010 0x0000000000000000
0xc000082200 这个地址也是个无妄之灾,[汗]。可以看到 key 变量本身变成双 16 了。我们在看一样栈上变量的样子:
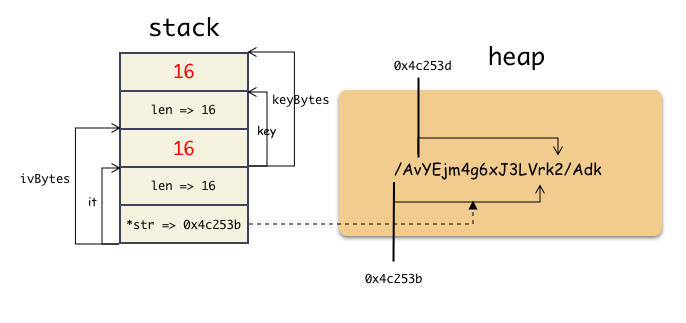
然后, StringToByte 函数把这 24 个字节复制给一个栈上的局部变量 keyBytes , keyBytes 的变量值如下:
*str => 16 (因为 key 被前面的人踩的,复制的时候就是 16)
len => 16
cap => 16
继续往后看,24,25 行:
fmt.Println(string(ivBytes))
fmt.Println(string(keyBytes))
这两行代码的作用是:
- 先把
ivBytes,keyBytes这两个slice转成string类型,然后打印出来, - 而
string(ivBytes)调用的函数是runtime.slicebytetostring
汇编能够看到 string(ivBytes) 实际的调用函数,如下:
0x0000000000491d2f <+671>: callq 0x447f70 <runtime.slicebytetostring>
再看一样 slicebytetostring 原型如下:
func slicebytetostring(buf *tmpBuf, b []byte) (str string) {
}
先说一下第一个参数,这是一个指针,这个指针就是 sliceheader 的第一个字段,也就是 Data 指针字段。
继续看 24 行代码的运行,这行代码为什么不会报错,因为 ivBytes 变量没事。ivBytes 能够转成 string ,其中 ivBytes 的变量如下:
*str => 0x4c253b
len => 16
cap => 16
但是 25 行代码则会出 panic(还记得吗?我们文章最开始的截图,panic 的位置就是 25 行),但是变量 key 被踩了呀,导致 keyBytes 这个变量也是错的。
*str => 16
len => 16
cap => 16
本应该是指针的字段,却活生生被踩成了 16 ,然后把这个值 16 当作指针传递到 slicebytetostring 函数里去转类型,如果这都不出非法地址的 panic ,那才真的见了鬼了。
这个就是为什么出 panic 的原因了。
思考第二个问题:为什么 22,23 调换下顺序就可以了?
怎么踩的内存,已经清楚了,但这位读者朋友,又深入问了一句:
是啊,为什么了?其实你只需要像上面一样,画一张图就就很简单了。22,23 调换一下顺序的区别就只在于换成先踩了谁的内存而已。
keyBytes := StringToByte(&key)
ivBytes := StringToByte(&iv)
由于 keyBytes := StringToByte(&key) 执行的时候踩的是后面的地址,但是 iv 地址是在 key 前面的,所以没有被踩到,是完好的内存,把 key 后面不知名的 8 字节踩了。最后 keyBytes 值如下:
*str => 0x4c253d
len => 16
cap => 16
所以在执行的 ivBytes := StringToByte(&iv) 的时候 ivBytes 的值正常:
*str => 0x4c253b
len => 16
cap => 16
当然了,最后还是顺手把变量 key 的头部踩成 16 了,不过此时已经没有影响,因为下面用的是 keyBytes, ivBytes ,所以程序自然可以正常运行。
思考第三个问题:怎么才能把程序改正确?
package main
import (
"fmt"
"reflect"
"unsafe"
)
func StringToByte(key *string) []byte {
slic := reflect.SliceHeader{}
slic = *(*reflect.SliceHeader)(unsafe.Pointer(key))
slic.Cap = slic.Len
b := *(*[]byte)(unsafe.Pointer(&slic))
return b
}
func main() {
decryptContent := "/AvYEjm4g6xJ3LVrk2/Adk"
iv := decryptContent[0:16]
key := decryptContent[2:18]
fmt.Println(iv)
fmt.Println(key)
ivBytes := StringToByte(&iv)
keyBytes := StringToByte(&key)
fmt.Println(string(ivBytes))
fmt.Println(string(keyBytes))
}
上面的程序我只改动了 StringToByte 函数,只改了 2 行代码。
slic := reflect.SliceHeader{}
slic = *(*reflect.SliceHeader)(unsafe.Pointer(key))
加了这两行代码之后,就不会踩到外面的内存了,从而杜绝踩内存导致的奇怪问题。具体原理小伙伴如果还有不清楚的,可以自己 gdb 分析下,或者找我交流。
当然了,这个读者朋友也是在研究和学习当中,现实项目中应该不至于出现这种奇怪的代码。但是这个小问题引发的思考却值得记录和学习。
总结
- Go 并非没有踩内存和其他内存问题,只要你想越过 Go 的类型校验,那么所有的内存问题可能你都要面对;
unsafe这个库已经这么明显的名字了,就是告诉你不安全,谨慎使用。所以说,除非有必须要用的理由,且明确知道自己的行为导致的后果才去使用,否则绕开走吧;- string 的管理结构是 16 字节,slice 的管理结构是 24 字节,记住哦;
坚持思考,方向比努力更重要。关注公众号:奇伢云存储,获取更多干货。
